百度NLP专栏
作者:百度NLP
「百度NLP」专栏是机器之心联合百度推出的专栏文章,探讨百度在自然语言处理领域的研究成果、实践经验与心得。该系列专栏以机器之心专访百度副总裁王海峰开篇(参阅:独家对话百度副总裁王海峰:NLP 的路还很长)。这篇文章为「百度NLP」专栏的第二篇,解读了百度在自动作诗方面的研究。
引子
「两个黄鹂鸣翠柳,一行白鹭上青天。」像这样优美的古诗,几乎每个人都在语文课堂上学习甚至背诵过。好的诗歌千古流传,深受广大人民的喜爱,然而诗歌创作却有很高的门槛。对于普通人来说,最多写几首打油诗,想写出意境优美而且朗朗上口的诗歌,几乎是不可能完成的任务。
创作诗歌对于人来说都很难,对于机器来说就更是难上加难了。虽然机器与人相比,在一些方面有着先天的优势,例如,机器有无穷无尽的词汇库可供选择,机器可以很容易的解决对仗、平仄和押韵等问题。但是,真正的诗歌是有灵魂的,诗歌本质上是在传达诗人的思想。机器自动创作在主题控制方面很弱,很难让整首诗都围绕一个统一的主题来生成。

百度在自动作诗领域的探索
百度在自动作诗方向做了很多探索。13 年手机百度 APP 推出了「为你写诗」功能,用户拍摄或上传一张图片,系统可以根据图片内容自动生成一首四句的古诗。这个功能受到了广大网民的好评,网友纷纷利用各种渠道晒出配诗的照片。2013 版「为你写诗」的核心算法是统计机器翻译技术(Statistical Machine Translation,简称 SMT),是为写诗 1.0 版本。写诗 1.0 版本可以生成通顺、押韵的古诗,在对仗方面做的也比较好,但是在主题相关性方面较差,其技术层面的原因稍后会进行详细分析。
2016 年,百度在手机百度 APP 和度秘 APP 上先后推出了新版「为你写诗」功能,可以让用户任意输入题目生成古诗,这个版本可以称为写诗 2.0 版本。该版本使用了一种基于主题规划的序列生成框架,很好地解决了上一版中主题相关性差的问题。
基于 PBMT 的写诗 1.0 版本
通过观察古诗可以看到,古诗的每两句诗之间存在很强的对应关系。以开篇那首杜甫的《绝句》为例,第一句「两个黄鹂鸣翠柳」和第二句「一行白鹭上青天」中,「两个」与「一行」相对,「黄鹂」与「白鹭」相对,「鸣翠柳」和「上青天」相对。这样的对应关系,通过基于短语的机器翻译模型(Phrase Based Machine Translation,PBMT)可以很好地学习出来。如果把一首古诗转换成前后相邻两句的句对形式,就得到一个平行语料库。这个语料库可以用于训练翻译模型。于是,诗歌生成问题就转换成相邻两句诗的翻译问题(从前一句翻译生成下一句)。对于第一句诗,由于没有前一句可以利用,需要单独生成。写诗 1.0 版本的解决方法是建立倒排索引,通过检索的方法得到第一句诗。整个框架如图一所示。
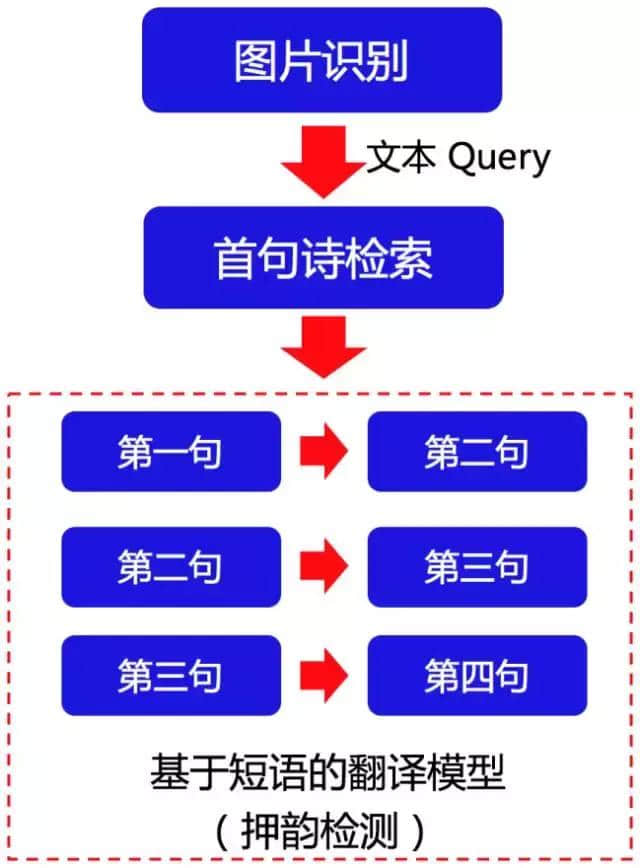
图一:写诗 1.0 版本框架图
从图一可以看到,用户输入的图片首先通过图片识别模块转换为文本 query,然后根据文本 query 检索得到第一句诗。也就是说,第一句诗实际上是从诗库里检索得到的,由人写出来的诗歌。得到首句诗之后,后面的第二、三、四句诗基于 PBMT 系统依次生成得到。
然而,这个框架有一个问题:用户 Query(诗歌题目)只能影响第一句诗的检索,无法对后面的诗句产生直接作用。这导致诗歌主题比较发散,甚至有可能出现诗句和主题矛盾的情况。举例来说,假设诗歌题目是「春天」,经过检索得到的首句诗是描写春天景色的,但是经过第一到第二,第二到第三,以及第三到第四句的传导之后,第四句有可能会出现描写下雪的与主题矛盾的诗句。
基于 NMT 的写诗 2.0 版本
2014 年 Sutskever 和 Bahdanau 分别在自己的论文中提出了一种基于循环神经网络的序列生成技术。Bahdanau 还进一步提出了一个带关注度(attention)机制的编码器-解码器框架。其基本思想是,把输入序列编码成一种稠密的向量表示形式,然后再通过解码器对向量表示进行解码,最终得到目标输出序列。而关注度机制的引入,使得模型可以在解码的时候动态计算对输入序列关注的位置。这个框架在机器翻译领域取得了巨大的成功,被称为神经网络机器翻译技术(Neural Machine Translation,简称 NMT)。
结合 NMT 技术,百度工程师提出了一套基于主题规划的诗歌生成框架,有效地提升了主题相关性,大幅提高了自动生成的诗歌质量。相关技术形成一篇论文,在 COLING 2016 会议上发表。(Zhe Wang, Wei He, Hua Wu, Haiyang Wu, Wei Li, Haifeng Wang, Enhong Chen. Chinese Poetry Generation with Planning based Neural Network. COLING 2016.)
主题规划技术首先根据用户 Query(诗歌题目)对要生成诗歌的内容进行规划,预测得到每一句诗的子主题,每一个子主题用一个单词来表示。这个过程和人类创作诗歌比较相似,诗人在创作之前往往会列出提纲,规划出每一句诗要描写的核心内容,然后再进行每句诗的创作。主题规划模型在生成每一句诗的时候,同时把上文生成的诗句和主题词一起输入来生成下一句诗。在这里,主题词的引入可以让生成的诗句不偏离主题,从而使整首诗都做到主题明确,逻辑顺畅。基于主题规划的诗歌生成框架(写诗 2.0 版本)如图二所示。

图二:写诗 2.0 框架(来源于论文 Wang et al. 2016)
图二中用户 Query 是「春天的桃花开了」。在主题规划阶段,经过主题词抽取和主题词扩展两个步骤,得到了要生成诗歌的四个主题词「春天」、「桃花」、「燕」和「柳」,这里限定每个词对应一句诗。和写诗 1.0 不同的是,利用 NMT 技术可以根据第一个主题词「春天」直接生成首句诗,在本例中得到「春天丽日照晴川」。在依次生成第二、三、四句诗歌的过程中,会考虑所有已生成的历史上文以及指定的主题词。具体地,用第一句诗句加主题词「桃花」生成得到第二句诗「十里桃花映满山」;用第一、二句诗加上主题词「燕」生成得到第三句诗「燕子呢喃寻旧梦」;用第一、二、三句诗加上主题词「柳」生成得到第四句诗「清风拂面柳如烟」。
写诗 2.0 的架构涉及到几个问题:(1)主题词如何抽取;(2)主题词如何扩展;(3)在基于 NMT 的生成过程中如何同时考虑上文和主题词。在这三个问题中,(1) 和 (2) 相对比较容易解决:主题词抽取主要考虑单词的重要程度,可以用 TextRank 等算法求解;主题词扩展可以看作一个根据已有单词预测后续单词词序列的问题,用语言模型或其他统计方法都可以求解。出于篇幅的考虑,这两个问题本文不展开进行详细的介绍,如果对细节感兴趣可以阅读论文(Wang et al. 2016)。
写诗 2.0 框架使用了两个编码器分别对历史上文和主题词进行编码。然后将得到的两个隐层向量序列进行拼接,最后再进行解码器的解码,整个过程如图三所示。
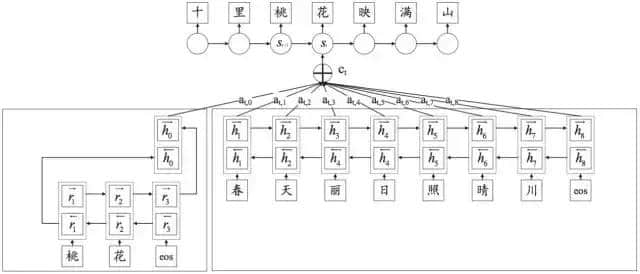
图三:基于主题规划的诗歌生成模型,同时考虑主题词「桃花」和历史上文「春天丽日照晴川」,经过基于关注度的 NMT 生成得到下一句诗「十里桃花映满山」。(来源 Wang et al. 2016)
图三中每一个汉字代表该汉字的 embedding 向量。首先,主题词「桃花」经过字级别双向 GRU 运算后,分别取正向和反向的最后一个向量拼接成一个新的向量。上文诗句「春天丽日照晴川」经过字级别双向 GRU 运算后,得到向量序列。把主题词向量和上文向量序列拼接之后,得到了新的向量序列。接下来,可以按照常规的基于关注度的 NMT 过程对向量序列进行解码,生成得到诗句「十里桃花映满山」。
需要注意的是,主题词和上文使用两套独立的编码器,其参数不共享,而在向量序列的拼接时,主题词向量会固定放在前面,这样在解码时解码器可以通过关注度机制自动控制对主题词关注的时机和程度。
对于图三所示的模型结构,在训练时需要构建 {上文诗句,主题词,待预测诗句} 的三元组作为训练数据。首先,我们把所有诗歌拆分并转换成为 {上文诗句,待预测诗句} 的二元组。然后,从「待预测诗句」中根据 TextRank 算法抽取出最重要的一个单词作为主题词,从而扩展得到 {上文诗句,主题词,待预测诗句} 的三元组数据。从「待预测诗句」中自动抽取主题词构建训练数据,这样训练得到的模型可以最大程度保证解码时主题词也会被「放置」进生成的诗句中。
论文 Wang et al. 对基于主题规划的诗歌生成方法进行了多个维度的实验评测。首先,从押韵程度(Poeticness)、流畅程度(Fluency)、主题相关度(Coherence)和是否有内容有意义(Meaning)等几个角度进行了人工评价。为了更好的进行对比,复现了目前主流的几种自动作诗技术:
SMT:基于统计机器翻译的自动作诗技术。
RNNLM:把所有诗句串联成一个单词序列,然后用循环神经网络语言模型(RNNLM)进行预测。
RNNPG:思想与 RNNLM 相近,区别在于依次生成诗歌的每一行。
ANMT:基于关注度的 NMT 模型。
PPG:基于主题规划的诗歌生成模型。
对于这些基线系统的详细介绍可以参考论文(Wang et al. 2016),本文不再展开讨论。实验结果如表一所示:
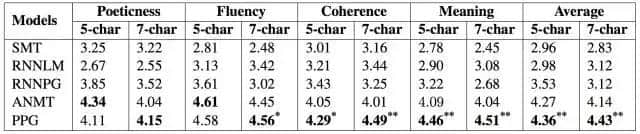
表一:PPG 方法与基线自动作诗方法的人工评价对比。其中 5-char 表示五言诗,7-char 表示七言诗
从表一可以看出,主题规划作诗方法几乎在所有的评测维度以及平均得分上都领先于其他基线系统,尤其在相关性和有意义性方面优势非常明显,只有在五言诗的押韵和流畅度评价上略低于 ANMT 系统(基于关注度的 NMT)。其可能的原因有两点:(1) ANMT 是一个非常强的基线系统,与 PPG 系统的区别只在于 PPG 考虑了主题词,而 ANMT 不考虑主题词;(2) 在五言诗的生成过程中,由于每句诗只有 5 个字,而 PPG 系统需要把主题词放置到生成的诗句中,这对于短句来说是很困难的事情,很容易造成不押韵或者流利度下降的情况。
随机盲测实验:机器自动作诗 PK 古代诗人
论文还做了一个非常有趣的随机盲测实验。找了 20 首由古代诗人写的古诗,和 20 首机器生成的诗打乱放在一起,让参评用户来猜哪一首是古代诗人写的。每一次会向参评用户展示 A 和 B 两首诗,其中一首为古代诗人所作,另一首为机器所生成。给用户三个选项:(1) A 诗是古代诗人写的;(2)B 诗是古代诗人写的;(3)无法判断哪首是古代诗人写的,放弃。给出选项 (3) 的目的是防止参评用户在无法判断的时候盲目猜测。
这个实验一共进行了两组,第一组实验邀请了 36 位普通用户(均为大学本科以上学历),称之为普通用户组(Normal Group)。第二组实验请了 4 位专修中国文学专业的用户进行实验,称之为专家组(Expert Group)。实验结果如图四所示。
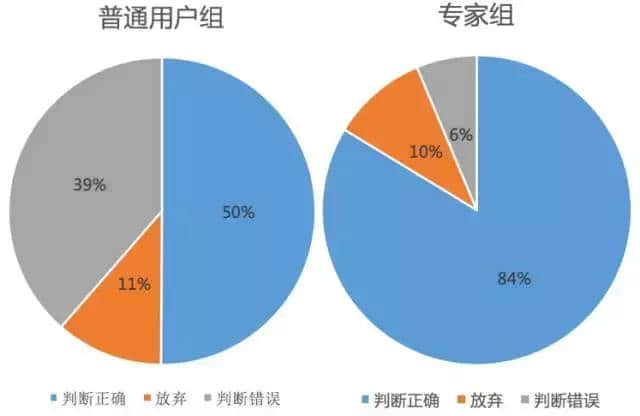
图四:自动作诗 vs. 古代诗人,普通和专家用户分别选出哪个是真正古代诗人的作品
从图四可以看出,对于普通用户,只有 50% 的真实诗歌可以被正确分辨出来,其余的 50% 用户判断错误或者放弃。而对于专家用户,判断正确的比例达到 84%,其余 16% 的诗歌被判断错误或者放弃。由此可见,对于普通用户而言,自动生成的诗歌质量几乎已经达到了以假乱真的程度,但是如果想骗过研究中国文学的专家,则还有很长的路要走。
下面给出盲测实验中的一组对比诗歌,其中一首是计算机自动生成的,另一首是宋代诗人葛绍体写的(如图五所示)。如果不看答案的话,读者是否能猜出哪一首是计算机写的,哪一首是诗人葛绍体所作呢?(答案在本文文末给出)

图五:随机盲测实验示例,两首诗中有一首是计算机生成的,另一首是宋代诗人葛绍体所作,请读者猜一下哪首是计算机写的诗。答案在本文文末揭晓。
主题规划技术中引入外部知识
在主题规划阶段,主题词不仅可以通过对语料的共现统计得到,还可以通过引入外部知识来扩展主题词。如果要为一位作家写一首诗(例如,Query=冰心),可以通过百度百科挖掘她的作品作为主题词(如《春水》、《繁星》、《往事》);如果要为一个现代名词写一首诗(例如,Query=啤酒),可以挖掘网页、搜索日志等数据,找出与啤酒相关的主题词(如香醇、清爽、醉)。主题规划使得我们可以灵活的控制诗歌的内容,从而实现一些语料库没有覆盖的主题诗歌生成。
自动作诗 PK 古代诗人答案揭晓
图五自动作诗 vs. 古代诗人的答案,左边「一夜秋凉雨湿衣」为计算机生成的诗歌,右边「荻花风里桂花浮」为宋代诗人葛绍体所作,出自《东山诗文选》。你猜对了吗?
如果想亲自体验一下为你写诗的效果,可以打开手机百度 APP,用语音输入「为你写诗」(一定要用语音),开启隐藏的写诗模式。也可以打开度秘 APP,输入「写诗」(语音或文字均可)。还可以输入「藏头诗」,「藏名诗」,体验不同类型的写诗功能。

「百度NLP」专栏主要关注百度自然语言处理技术发展进程,报道前沿资讯和动态,分享技术专家的行业解读与深度思考。
